⚠️ Disclaimer
La méthode que je présente ici correspond à ma propre démarche d’apprentissage. Elle peut contenir des approximations ou des erreurs, car j’apprends et je progresse chaque jour un peu plus. Ne prenez donc pas ce que je fais comme une référence absolue, mais plutôt comme un retour d’expérience personnel.
Du monitoring métrique au monitoring d’événements
Après avoir déployé ma stack Prometheus/Grafana et configuré le monitoring SNMP de mes équipements réseau, une lacune m’était devenue évidente : je pouvais observer les métriques en temps réel, mais je n’avais aucune visibilité sur ce qui se passait réellement sur les machines. Un pic de CPU sur le pfSense apparaissait sur le dashboard, mais impossible de savoir pourquoi. C’était un peu comme regarder un tachymètre sans pouvoir consulter les logs du moteur.
Ce projet marque la transition entre un monitoring purement “performatif” (est-ce que mon infrastructure tourne ?) et un monitoring qui répond aux vraies questions de sécurité : que s’est-il passé, quand, d’où ça vient, et est-ce normal ? C’est en filigrane la démarche d’un SOC réel, où les métriques et les logs sont deux sources complémentaires, pas alternatives.
Mon objectif était de déployer un pipeline centralisé pour collecter les logs du pfSense, du NAS Synology et du Mac, puis de tester les premières alertes mail en temps réel. Rien de révolutionnaire, mais c’était nouveau pour moi dans mon homelab.
Le choix de la stack : Loki plutôt qu’ELK
Pour cette centralisation, j’ai écarté assez rapidement Elasticsearch/ELK. C’est une stack puissante, certes, mais elle demande des ressources énormes, surtout Elasticsearch seul qui dévore la RAM. Pour un homelab avec des serveurs modestes, c’était disproportionné.
J’ai choisi Loki pour plusieurs raisons. D’abord, il est nativement intégré à Grafana, sans besoin de configurer une interface de requête parallèle. Ensuite, Loki n’indexe que les labels des logs, pas leur contenu complet comme Elasticsearch. Cette approche est contre-intuitive au départ (comment chercher dans les logs sans indexation complète ?), mais elle rend le système beaucoup plus léger. Enfin, Loki fonctionne parfaitement avec Promtail, l’agent officiel de l’écosystème Grafana Labs.
Pour la collecte, Promtail s’imposait : il écoute nativement le Syslog UDP sans configuration complexe. Fluent Bit aurait été une alternative plus polyvalente, mais plus coûteuse en configuration.
Pour les alertes, j’ai utilisé le système d’alerting natif de Grafana plutôt que de déployer un Alertmanager séparé. Grafana Alerting est plus simple à maintenir pour un homelab et largement suffisant pour mes besoins actuels.
Architecture et flux des logs
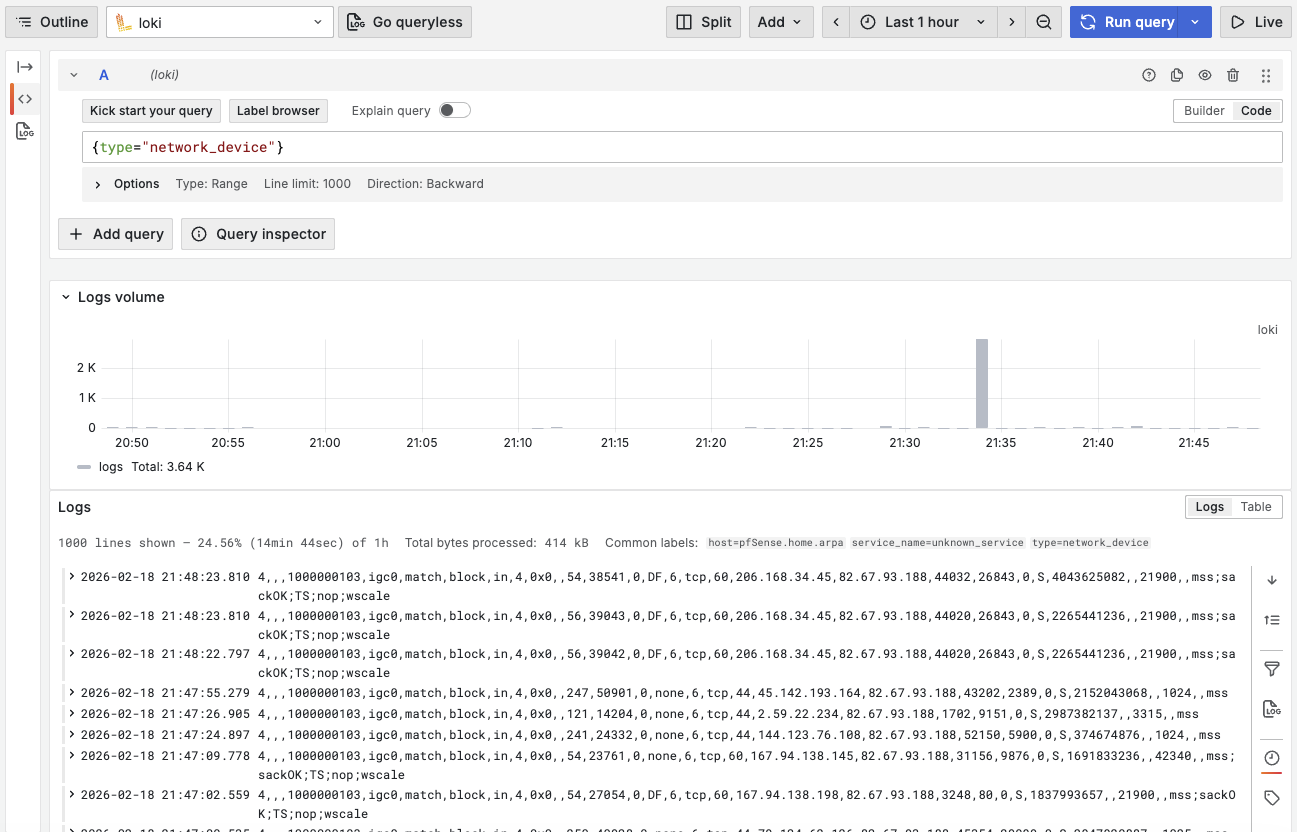
Le pipeline est simple : pfSense, NAS Synology et Mac envoient leurs logs en Syslog UDP vers Promtail (port 1514). Promtail les parse, ajoute des labels (notamment le hostname extrait du message), puis les envoie à Loki qui les stocke et les indexe. Grafana explore ensuite ces logs via LogQL, la version Loki de PromQL.
[pfSense] ──┐
[NAS Syno] ──┤──► [Promtail :1514/UDP] ──► [Loki :3100] ──► [Grafana :3000]
[Mac /log] ──┘
La beauté du Syslog UDP, c’est son mode “fire and forget” : les logs partent vers le collecteur sans attendre d’acquittement. Si la connexion est surchargée, on perd quelques logs plutôt que de ralentir le firewall avec des acquittements TCP. Ce compromis a du sens sur l’infrastructure d’une entreprise qui n’a pas le choix. Dans un homelab, c’est moins critique, mais c’est bon à comprendre.
La mise en œuvre, avec ses pièges
L’ajout de Loki et Promtail au docker-compose.yml existant s’est fait sans douleur. Le vrai piège attendait ailleurs. Quand j’ai essayé de faire remonter les logs, rien ne venait. J’ai passé un bon moment à déboguer avant de réaliser le problème : le port UDP n’était pas configuré correctement.
En Docker, mapper un port UDP demande une syntaxe spécifique : 1514:1514/udp. Oublier le suffixe /udp fait que Docker le mappe en TCP par défaut, silencieusement, sans message d’erreur. Les logs ne remontent jamais, et on se demande pourquoi pendant une heure. La vérification avec docker port promtail révèle l’erreur : le port n’apparaît que comme TCP.
Une fois ce détail réglé, Promtail a pu recevoir les paquets UDP. L’étape suivante était la configuration du relabeling : extraire le hostname du message Syslog et le transformer en label host pour que Grafana puisse filtrer. C’est là qu’on comprend la philosophie Loki : on paie le coût de l’extraction au moment du parsing, pas au moment de la requête.
Le fichier promtail-config.yaml ressemble à ceci :
| |
Ce relabeling est indispensable. Sans lui, tous les logs arrivent avec le même label et on ne peut pas les distinguer dans Grafana.
Configurer pfSense et le NAS
Sur pfSense, la configuration est simple : Status → System Logs → Settings, activer le remote logging, pointer vers l’IP du Mac et le port 1514. RFC 5424 est recommandé pour une meilleure structuration.
Sur le NAS Synology, il y a un paquet appelé “Centre de journaux” qui permet d’envoyer les logs vers un serveur Syslog externe. Même adresse, même port.
La validation se fait en deux étapes. D’abord, un sudo tcpdump -i any udp port 1514 sur le Mac pour vérifier que les paquets arrivent au niveau réseau. Ensuite, un coup d’œil dans l’onglet Explore de Grafana pour vérifier que les logs sont indexés avec les bons labels.
Alertes mail : configurer le premier test
Avec les métriques SNMP déjà en place, j’ai décidé de tester les alertes mail en créant une règle simple : alerter si le NAS devient injoignable pendant 2 minutes. C’était un cas de test idéal, facile à déclencher manuellement.
Dans Grafana, les alertes se configurent en deux étapes. D’abord la Contact Point, le canal où envoyer les notifications. J’ai choisi Email, configuré l’SMTP en pointant vers Gmail, et c’est là que ça s’est compliqué. Mon mot de passe Gmail ne fonctionnait pas. Google demande un mot de passe d’application si l’authentification à deux facteurs est activée, ce qui était mon cas. Une fois ce détail réglé, la Contact Point était opérationnelle.
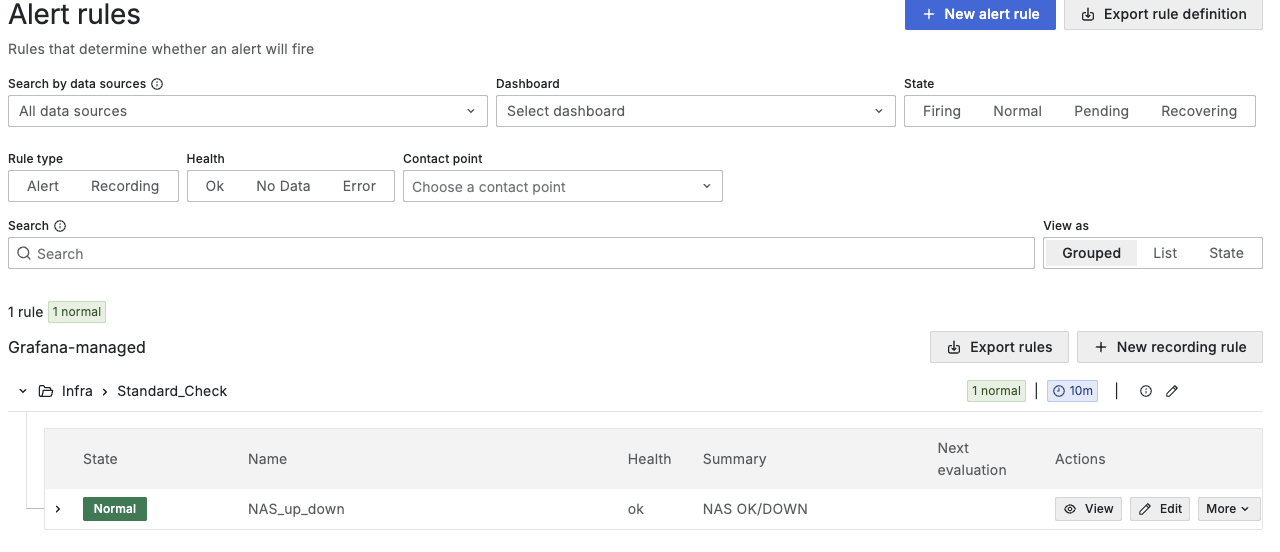
Ensuite, la Alert Rule. Elle repose sur une métrique Prometheus simple : up{job="synology-nas-snmp"}. Cette métrique vaut 1 quand le NAS répond, 0 quand il ne répond pas. La condition == 0 pendant 2 minutes suffit à déclencher l’alerte.
| |
J’ai testé en désactivant SNMP sur le NAS. Au bout de 2 minutes, l’alerte est passée de Normal à Pending, puis à Firing. L’email est arrivé avec le résumé, la valeur du problème, et le nom du composant affecté. Ça a fonctionné du premier coup.
Ce que j’en retiens
Techniquement, j’ai appris des choses évidentes une fois qu’on les connaît. La distinction entre métriques (time-series numériques) et logs (événements textuels) est centrale : ce ne sont pas deux façons de voir la même chose, ce sont deux représentations complémentaires. Les métriques répondent à “comment ça va”, les logs répondent à “que s’est-il passé”. Les deux sont nécessaires.
Le concept de labeling Loki m’a forcé à penser différemment par rapport à Elasticsearch. Avec Elasticsearch, on indexe tout et on filtre à la requête. Avec Loki, on décide des labels à l’avance et on les utilise pour naviguer. C’est une contrainte qui rend le système plus efficace.
Le protocole Syslog UDP lui-même a du sens. “Fire and forget” signifie qu’on ne ralentit pas le firewall en attendant un acquittement. Sur une infrastructure surchargée, on peut perdre quelques logs pour ne pas dégrader les performances. C’est un compromis accepté largement dans le secteur.
Sur le plan méthodologique, une chose m’a marqué : la validation par étapes. J’aurais pu partir directement sur Loki et Grafana et chercher pourquoi ça ne marche pas. À la place, j’ai vérifié le flux réseau avec tcpdump d’abord, puis j’ai validé Loki avant de construire les dashboards. Ça m’a sauvé des heures de debugging.
Tester les alertes concrètement était aussi important. Une règle visible dans Alerting → Alert Rules n’est pas une preuve qu’elle fonctionne. J’ai désactivé le NAS, attendu 2 minutes, et vérifié que l’email arrivait. Seul ce test en conditions réelles valide le tout.
Les erreurs à éviter sont simples à énoncer, difficiles à ne pas faire. Oublier le /udp dans la déclaration du port Docker est une erreur silencieuse : Docker ne prévient pas, il mappe juste en TCP. Utiliser son mot de passe Gmail principal au lieu d’un mot de passe d’application avec 2FA activé bloque le SMTP sans message d’erreur clair. Ne pas tester l’alerte avant de conclure qu’elle fonctionne laisse la porte ouverte à une mauvaise surprise à 3h du matin.
Prochaines étapes
Le prochain chantier naturel est d’intégrer les logs MikroTik. Le switch supporte Syslog natif, il suffira d’ajouter la destination dans RouterOS. Côté alerting, je veux enrichir les règles existantes : CPU du Mac, débit anormal, patterns suspects dans les logs.
À moyen terme, Alertmanager offrira plus de flexibilité : groupement des alertes, silences temporaires, escalade vers un Slack ou un PagerDuty. Grafana Alerting natif est suffisant pour commencer, mais Alertmanager c’est un autre niveau.
L’horizon qui me motive vraiment, c’est une analyse sémantique des logs par IA locale. Ingérer les logs Loki dans une base vectorielle, les soumettre à un LLM local via Ollama, générer un rapport de sécurité quotidien en langage naturel. Quand on a du contenu brut, c’est facile de manquer le signal. Une IA qui résume, c’est peut-être la réponse.